程序员必须掌握哪些算法?
程序员必须掌握哪些算法?
-
算法一:快速排序算法
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
算法步骤:
1 从数列中挑出一个元素,称为 “基准”(pivot),
2 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
算法二:堆排序算法
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的平均时间复杂度为Ο(nlogn) 。
算法步骤:
创建一个堆H[0..n-1]
把堆首(最大值)和堆尾互换
3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置
4. 重复步骤2,直到堆的尺寸为1
算法三:归并排序
归并排序(Merge sort,台湾译作:合并排序)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
算法步骤:
1. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2. 设定两个指针,最初位置分别为两个已经排序序列的起始位置
3. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4. 重复步骤3直到某一指针达到序列尾
5. 将另一序列剩下的所有元素直接复制到合并序列尾
算法四:二分查找算法
二分查找算法是一种在有序数组中查找某一特定元素的搜索算法。搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜 素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组 为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。折半搜索每次把搜索区域减少一半,时间复杂度为Ο(logn) 。
算法五:BFPRT(线性查找算法)
BFPRT算法解决的问题十分经典,即从某n个元素的序列中选出第k大(第k小)的元素,通过巧妙的分 析,BFPRT可以保证在最坏情况下仍为线性时间复杂度。该算法的思想与快速排序思想相似,当然,为使得算法在最坏情况下,依然能达到o(n)的时间复杂 度,五位算法作者做了精妙的处理。
算法步骤:
1. 将n个元素每5个一组,分成n/5(上界)组。
2. 取出每一组的中位数,任意排序方法,比如插入排序。
3. 递归的调用selection算法查找上一步中所有中位数的中位数,设为x,偶数个中位数的情况下设定为选取中间小的一个。
4. 用x来分割数组,设小于等于x的个数为k,大于x的个数即为n-k。
5. 若i==k,返回x;若i<k,在小于x的元素中递归查找第i小的元素;若i>k,在大于x的元素中递归查找第i-k小的元素。
终止条件:n=1时,返回的即是i小元素。
算法六:DFS(深度优先搜索)
深度优先搜索算法(Depth-First-Search),是搜索算法的一种。它沿着树的深度遍历树的节点,尽可能深的搜索树的分 支。当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发 现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。DFS属于盲目搜索。
深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。一般用堆数据结构来辅助实现DFS算法。
深度优先遍历图算法步骤:
1. 访问顶点v;
2. 依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
3. 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
上述描述可能比较抽象,举个实例:
DFS 在访问图中某一起始顶点 v 后,由 v 出发,访问它的任一邻接顶点 w1;再从 w1 出发,访问与 w1邻 接但还没有访问过的顶点 w2;然后再从 w2 出发,进行类似的访问,… 如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。
接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止。
算法七:BFS(广度优先搜索)
广度优先搜索算法(Breadth-First-Search),是一种图形搜索算法。简单的说,BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。如果所有节点均被访问,则算法中止。BFS同样属于盲目搜索。一般用队列数据结构来辅助实现BFS算法。
算法步骤:
1. 首先将根节点放入队列中。
2. 从队列中取出第一个节点,并检验它是否为目标。
如果找到目标,则结束搜寻并回传结果。
否则将它所有尚未检验过的直接子节点加入队列中。
3. 若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
4. 重复步骤2。
算法八:Dijkstra算法
戴克斯特拉算法(Dijkstra’s algorithm)是由荷兰计算机科学家艾兹赫尔·戴克斯特拉提出。迪科斯彻算法使用了广度优先搜索解决非负权有向图的单源最短路径问题,算法最终得到一个最短路径树。该算法常用于路由算法或者作为其他图算法的一个子模块。
该算法的输入包含了一个有权重的有向图 G,以及G中的一个来源顶点 S。我们以 V 表示 G 中所有顶点的集合。每一个图中的边,都是两个顶点所形成的有序元素对。(u, v) 表示从顶点 u 到 v 有路径相连。我们以 E 表示G中所有边的集合,而边的权重则由权重函数 w: E → [0, ∞] 定义。因此,w(u, v) 就是从顶点 u 到顶点 v 的非负权重(weight)。边的权重可以想像成两个顶点之间的距离。任两点间路径的权重,就是该路径上所有边的权重总和。已知有 V 中有顶点 s 及 t,Dijkstra 算法可以找到 s 到 t的最低权重路径(例如,最短路径)。这个算法也可以在一个图中,找到从一个顶点 s 到任何其他顶点的最短路径。对于不含负权的有向图,Dijkstra算法是目前已知的最快的单源最短路径算法。
算法步骤:
1. 初始时令 S={V0},T={其余顶点},T中顶点对应的距离值
若存在<v0,vi>,d(V0,Vi)为<v0,vi>弧上的权值
若不存在<v0,vi>,d(V0,Vi)为∞
2. 从T中选取一个其距离值为最小的顶点W且不在S中,加入S
3. 对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值
重复上述步骤2、3,直到S中包含所有顶点,即W=Vi为止
算法九:动态规划算法
动态规划(Dynamic programming)是一种在数学、计算机科学和经济学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。 动态规划常常适用于有重叠子问题和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再合并子问题的解以得出原问题的解。 通常许多 子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,从而减少计算量: 一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个 子问题解之时直接查表。 这种做法在重复子问题的数目关于输入的规模呈指数增长时特别有用。
关于动态规划最经典的问题当属背包问题。
算法步骤:
1. 最优子结构性质。如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。最优子结构性质为动态规划算法解决问题提供了重要线索。
2. 子问题重叠性质。子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。 动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是 在表格中简单地查看一下结果,从而获得较高的效率。
算法十:朴素贝叶斯分类算法
朴素贝叶斯分类算法是一种基于贝叶斯定理的简单概率分类算法。贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下, 如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。
朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法,换言之朴素贝叶斯模型能工作并没有用到贝叶斯概率或者任何贝叶斯模型。


 2019-12-06 09:47:31
2019-12-06 09:47:31 -
根据我的经验,最好算法课本上的都知道一下干啥用的。但绝大部分不需要深入。因为一般来说你90%用不上。而用上的时候90%应该该去找现成测试通过的。
比如说,排序算法,JAVA里面默认的是归并,并且当足够短的时候是冒泡。哈希算法里面当哈希值一样的时候,够短用链表,长了红黑树。
你会发现实际往往是多重场景,而通常你要做的只是选择更合适的,根本不需要自己写。只有非常罕见的场景,才要自己写一个。
这种情况下,算法没有说那种必须掌握,而是知道的多更好一些。需要知道各自优缺点,应用场景。另外,如果不是专门的算法工程师,设计模式去学一下可能也不错。
2020-06-09 04:22:24 -
起码一些教材式经典算法要知道,包括排序算法,图算法,串匹配算法,运输流算法,还有一些经典的数学计算算法,比如大规模矩阵乘法,傅里叶积分算法。等等有很多,虽然不一定都用的到,但这些耳熟能详的经典算法必须有所了解。等到工作后会接触到相关的专业算法,再加以学习
2019-12-19 19:58:49 -
楼上写的太多了,一般程序员都不会掌握的,把有限的时间花费到重要的算法上。
1.快速排序算法
2.归并排序算法
3.堆排序算法
4.二分查找算法
5.BFPRT线性查找算法
6.DFS深度优先搜索
7.BFS广度优先算法
8.动态规划
9.朴素贝叶斯分类
希望以帮助哈!
2019-12-17 00:35:35 -
一、算法最最基础
1、时间复杂度
2、空间复杂度
一般最先接触的就是时间复杂度和空间复杂度的学习了,这两个概念以及如何计算,是必须学的,也是必须最先学的,主要有最大复杂度、平均复杂度等,直接通过博客搜索学习即可。
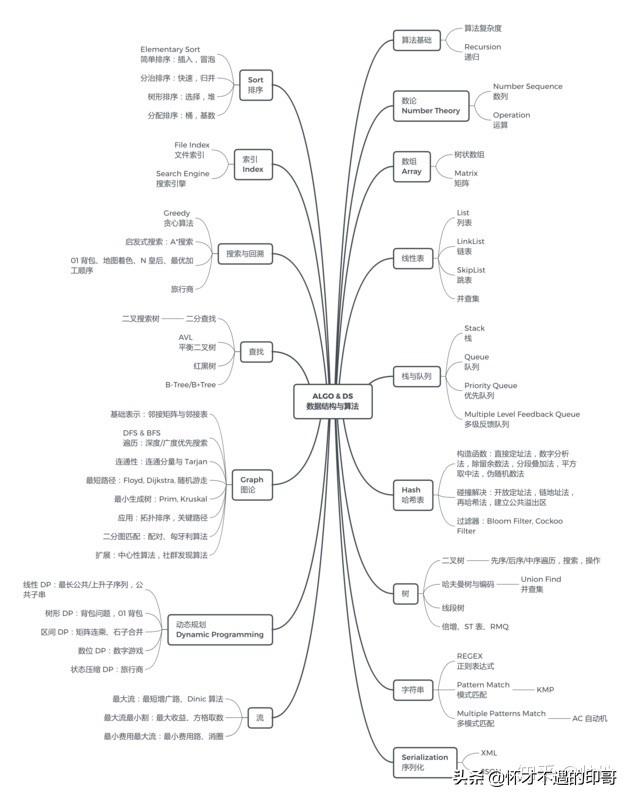
二、基础数据结构
1、线性表
列表(必学)
链表(必学)
跳跃表(知道原理,应用,最后自己实现一遍)
并查集(建议结合刷题学习)
不用说,链表、列表必须,不过重点是链表。
2、栈与队列
栈(必学)
队列(必学)
优先队列、堆(必学)
多级反馈队列(原理与应用)
特别是优先队列,再刷题的时候,还是经常用到的,队列与栈,是最基本的数据结构,必学。可以通过博客来学习。
3、哈希表(必学)
碰撞解决方法:开放定址法、链地址法、再次哈希法、建立公共溢出区(必学)
布隆过滤器
4、树
二叉树:各种遍历(递归与非递归)(必学)
哈夫曼树与编码(原理与应用)
AVL树(必学)
B 树与 B+ 树(原理与应用)
前缀树(原理与应用)
红黑树(原理与应用)
线段树(原理与应用)
5、数组
树状数组
矩阵(必学)
树状数组其实我也没学过,,,,
三、各种常见算法
1、十大排序算法
简单排序:插入排序、选择排序、冒泡排序(必学)
分治排序:快速排序、归并排序(必学,快速排序还要关注中轴的选取方式)
分配排序:桶排序、基数排序
树状排序:堆排序(必学)
其他:计数排序(必学)、希尔排序
对于十大算法的学习,假如你不大懂的话,那么我还是挺推荐你去看书的,因为看了书,你可能不仅仅知道这个算法怎么写,还能知道他是怎么来的。推荐书籍是《算法第四版》,这本书讲的很详细,而且配了很多图演示,还是挺好懂的。
2、图论算法
图的表示:邻接矩阵和邻接表
遍历算法:深度搜索和广度搜索(必学)
最短路径算法:Floyd,Dijkstra(必学)
最小生成树算法:Prim,Kruskal(必学)
实际常用算法:关键路径、拓扑排序(原理与应用)
二分图匹配:配对、匈牙利算法(原理与应用)
拓展:中心性算法、社区发现算法(原理与应用)
图还是比较难的,不过我觉得图涉及到的挺多算法都是挺实用的,例如最短路径的计算等,图相关的,我这里还是建议看书的,可以看《算法第四版》。
漫画:什么是 “图”?(修订版)
漫画:深度优先遍历 和 广度优先遍历
漫画:图的 “最短路径” 问题
漫画:Dijkstra 算法的优化
漫画:图的 “多源” 最短路径
3、搜索与回溯算法
贪心算法(必学)
启发式搜索算法:A*寻路算法(了解)
地图着色算法、N 皇后问题、最优加工顺序
旅行商问题
这方便的只是都是一些算法相关的,我觉得如果可以,都学一下。像贪心算法的思想,就必须学的了。建议通过刷题来学习,leetcode 直接专题刷。
4、动态规划
树形DP:01背包问题
线性DP:最长公共子序列、最长公共子串
区间DP:矩阵最大值(和以及积)
数位DP:数字游戏
状态压缩DP:旅行商
我觉得动态规划是最难的一个算法思想了,记得当初第一次接触动态规划的时候,是看01背包问题的,看了好久都不大懂,懵懵懂懂,后面懂了基本思想,可是做题下不了手,但是看的懂答案。一气之下,再leetcdoe专题连续刷了几十道,才掌握了动态规划的套路,也有了自己的一套模板。不过说实话,动态规划,是考的真他妈多,学习算法、刷题,一定要掌握。这里建议先了解动态规划是什么,之后 leetcode 专题刷,反正就一般上面这几种题型。后面有时间,我也写一下我学到的套路,有点类似于我之前写的递归那样,算是一种经验。也就是我做题时的模板,不过感觉得写七八个小时,,,,,有时间就写。之前写的递归文章:为什么你学不会递归?告别递归,谈谈我的一些经验
5、字符匹配算法
正则表达式
模式匹配:KMP、Boyer-Moore
我写过两篇字符串匹配的文章,感觉还不错,看了这两篇文章,我觉得你就差不多懂 kmp 和 Boyer-Moore 了。
字符串匹配Boyer-Moore算法:文本编辑器中的查找功能是如何实现的?
6、流相关算法
最大流:最短增广路、Dinic 算法
最大流最小割:最大收益问题、方格取数问题
最小费用最大流:最小费用路、消遣
这方面的一些算法,我也只了解过一些,感兴趣的可以学习下。
 2019-12-16 08:41:18
2019-12-16 08:41:18 -
使用红黑树来解决Hash碰撞冲突的问题;
计算sizeStamp的时候,调用了Interger中的方法,使用位运算来求出给定数leading zero的数量,当然使用sizeStamp这种方式也算是另辟蹊径吧;
presize中,使用位运算来求出不小于一个数的最小的2的幂;
transfer中,table[i]指向的链表或红黑树中的所有节点,根据hash\u0026n是否为0分别放在table[i]和table[i+n]中,之所以可以这样划分,是因为table数组的长度n是2的幂,这种数字关系挺微妙。
DelayQueue
take中,使用leader/follower模式,避免线程切换的开销,从而达到减少等待时间的目的。
PriorityBlockingQueue
使用数组维护了一个最小堆。
2019-12-06 11:39:29 -
你可以去力扣上看看,基本都得掌握
2019-12-06 09:23:46 -
去把数据结构的算法搞懂你就稳了
2019-12-06 11:44:58 -

一般的应用开发,什么算法也不需要。
高级开发,排序,数组,指针,循环
2019-12-06 12:14:27 -
这要看,你想做哪个方面的程序员。
程序员有后端、前端、移动端、大数据、AI等。如果只是纯前端和移动端而言,算法掌握基础的排序、红黑树、哈希等也就差不多了,更加高深的也用不到,更多的是系统API就提供了很多算法方法。总不见得,写的能比系统的好吧。如果只是想作为一个普通的程序员,不想着往高级和架构方向走,那么不接触算法,你会发现也行,活照做。但是呢,水往高处流,算法还是需要的。尤其像大数据和人工智能,算法是必须会的,而算法而言,就是数学。
人工智能来说,线性代数、概率论等是一个很重要的,不单是算法可以来解释。还有信息论,计算信息传递熵。个人推荐,可以看下国外的程序设计大赛,里面有很多考验算法的,平时开发中,多思考怎样减少信息传递,提高代码效率,这也是算法的一种。
必须了解,掌握的:1.树,2.哈希,3.正则,4.图算法,5.串匹配,6.运输流
但是更多的是掌握那些经典的数学计算算法,这才是根本。算法脱离不了数学,算法玩的好的,一般数学都好。推荐平时,多去看看《线性代数》《高等数学》还有偏向计算机的算法书籍,会有所帮助。再去看看国外程序设计大赛的题目,别人写的程序,从中会对算法有更大的启发。但作为程序员,算法只是一部分,更重要的是怎样快速迭代,减少开发成本,怎样贴合业务等。
2019-12-21 22:30:26 -
排序算法是基础,一定要会,然后再学tree,就差不多。
2019-12-18 07:27:28 -
从自己本身来看,数据结构里的算法都需要知道,从面试角度来说,二叉树、链表、冒泡、快速就必须要能写出来
2019-12-09 08:33:04 -
优秀程序员该学的32个算法!!
1、A搜索算法——图形搜索算法,作为启发式搜索算法中的一种,这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法,常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。
从给定起点到给定终点计算出路径。其中使用了一种启发式的估算,为每个节点估算通过该节点的最佳路径,并以之为各个地点排定次序。算法以得到的次序访问这些节点。因此,A*搜索算法是最佳优先搜索的范例。
2、集束搜索(又名定向搜索,Beam Search)——最佳优先搜索算法的优化。使用启发式函数评估它检查的每个节点的能力。不过,集束搜索只能在每个深度中发现最前面的m个最符合条件的节点,m是固定数字——集束的宽度。
通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率
算法的工作流程如下:
使用广度优先策略建立搜索树,在树的每一层,按照启发代价对节点进行排序,然后仅留下预先确定的个数(Beam Width-集束宽度)的节点,仅这些节点在下一层次继续扩展,其他节点就被剪掉了。
将初始节点插入到list中,
将给节点出堆,如果该节点是目标节点,则算法结束;
否则扩展该节点,取集束宽度的节点入堆。然后到第二步继续循环。
算法结束的条件是找到最优解或者堆为空。
3、二分查找(Binary Search)——在线性数组中找特定值的算法,每个步骤去掉一半不符合要求的数据。
二分查找的基本思想是:
设R[low..high]是当前的查找区间
(1)首先确定该区间的中点位置:
(2)然后将待查的K值与R[mid].key比较:若相等,则查找成功并返回此位置,否则须确定新的查找区间,继续二分查找,具体方法如下:
① 若R[mid].key\u003eK,则由表的有序性可知R[mid..n].keys均大于K,因此若表中存在关键字等于K的结点,则该结点必定是在位置mid左边的子表R[1..mid-1]中,故新的查找区间是左子表R[1..mid-1]。
② 若R[mid].key\u003cK,则要查找的K必在mid的右子表R[mid+1..n]中,即新的查找区间是右子表R[mid+1..n]。下一次查找是针对新的查找区间进行的。
4、分支界定算法(Branch and Bound)——在多种最优化问题中寻找特定最优化解决方案的算法,特别是针对离散、组合的最优化。
搜索策略是:
A产生当前扩展节点的所有孩子节点, 并且在活结点链表中删除当前拓展节点;对于一般的求最优值和资源问题是二叉树, 对于求最短路径这样的图论问题, 是一般的树
B在产生的孩子节点中,剪掉那些不可能产生可行解(或最优解)的节点;(使用限定条件)
C将其余所有的孩子节点加入活节点链表;
D从活结点表中选择下一个活结点作为新的扩展节点;
E遇到层结束标记(采取不同的数据结构实现可能不同, 加入新的结束标记)
如此循环,直到找到问题的可行解(或最优解)或者活结点表为空。
分支界定法的思想是:首先确定目标值的上下界, 边搜索边减掉搜索树的某些枝, 提高搜索效率。
5、Buchberger算法——一种数学算法,可将其视为针对单变量最大公约数求解的欧几里得算法和线性系统中高斯消元法的泛化。
6、数据压缩——采取特定编码方案,使用更少的字节数(或是其他信息承载单元)对信息编码的过程,又叫来源编码。
7、Diffie-Hellman密钥交换算法——一种加密协议,允许双方在事先不了解对方的情况下,在不安全的通信信道中,共同建立共享密钥。该密钥以后可与一个对称密码一起,加密后续通讯。
8、Dijkstra算法——针对没有负值权重边的有向图,计算其中的单一起点最短算法。
9、离散微分算法(Discrete differentiation)
10、动态规划算法(Dynamic Programming)——展示互相覆盖的子问题和最优子架构算法
11、欧几里得算法(Euclidean algorithm)——计算两个整数的最大公约数。最古老的算法之一,出现在公元前300前欧几里得的《几何原本》。
12、期望-最大算法(Expectation-maximization algorithm,又名EM-Training)——在统计计算中,期望-最大算法在概率模型中寻找可能性最大的参数估算值,其中模型依赖于未发现的潜在变量。EM在两个步骤中交替计算,第一步是计算期望,利用对隐藏变量的现有估计值,计算其最大可能估计值;第二步是最大化,最大化在第一步上求得的最大可能值来计算参数的值。
13、快速傅里叶变换(Fast Fourier transform,FFT)——计算离散的傅里叶变换(DFT)及其反转。该算法应用范围很广,从数字信号处理到解决偏微分方程,到快速计算大整数乘积。
14、梯度下降(Gradient descent)——一种数学上的最优化算法。
15、哈希算法(Hashing)
Hash算法是一种只能加密不能解密的算法,可以将任意长度的信息转成杂乱的固定长度的字符串,叫做Hash值,又称“消息摘要”(Message Digest)
也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
由于非对称算法的运算速度较慢,所以在数字签名协议中,哈希函数扮演了一个重要的角色而被用于数字签名。
哈希算法具有以下2个特点:
1.输入值只要改变一点,输出的hash值会天差地别。因此只有完全一样的输入值才能达到完全一样的输出值2.输入值和输出值之间没有规律,所以不能通过输出值反推出输入值。
16、堆排序(Heaps)
指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。
17、Karatsuba乘法——需要完成上千位整数的乘法的系统中使用,比如计算机代数系统和大数程序库,如果使用长乘法,速度太慢。该算法发现于1962年。
18、LLL算法(Lenstra-Lenstra-Lovasz lattice reduction)——以格规约(lattice)基数为输入,输出短正交向量基数。LLL算法在以下公共密钥加密方法中有大量使用:背包加密系统(knapsack)、有特定设置的RSA加密等等。
19、最大流量算法(Maximum flow)——该算法试图从一个流量网络中找到最大的流。它优势被定义为找到这样一个流的值。最大流问题可以看作更复杂的网络流问题的特定情况。最大流与网络中的界面有关,这就是最大流-最小截定理(Max-flow min-cut theorem)。Ford-Fulkerson 能找到一个流网络中的最大流。
20、合并排序(Merge Sort)
具体步骤如下:
将待排序的数组分成左右两部分。
再将这两部分分别分成左右两部分。
一直分下去,直到不可分(每部分只有一个元素)。
由于数组被分成许多的单个数据,比较起来就简单了,然后开始合并,合并的同时排序。
持续合并直到得到排好序的数组。
下面这幅图可以帮助你理解算法过程:
21、牛顿法(Newton's method)——求非线性方程(组)零点的一种重要的迭代法。
同梯度下降法一样,是一种优化算法,其应用如可解决logistic回归于分类问题中的似然函数最大化。
其是一种用于求函数零点的数值方法。
22、Q-learning学习算法——这是一种通过学习动作值函数(action-value function)完成的强化学习算法,函数采取在给定状态的给定动作,并计算出期望的效用价值,在此后遵循固定的策略。Q-leanring的优势是,在不需要环境模型的情况下,可以对比可采纳行动的期望效用。
23、两次筛法(Quadratic Sieve)——现代整数因子分解算法,在实践中,是目前已知第二快的此类算法(仅次于数域筛法Number Field Sieve)。对于110位以下的十位整数,它仍是最快的,而且都认为它比数域筛法更简单。
24、RANSAC——是“RANdom SAmple Consensus”的缩写。该算法根据一系列观察得到的数据,数据中包含异常值,估算一个数学模型的参数值。其基本假设是:数据包含非异化值,也就是能够通过某些模型参数解释的值,异化值就是那些不符合模型的数据点。
25、RSA——公钥加密算法。首个适用于以签名作为加密的算法。RSA在电商行业中仍大规模使用,大家也相信它有足够安全长度的公钥。
26、Schönhage-Strassen算法——在数学中,Schönhage-Strassen算法是用来完成大整数的乘法的快速渐近算法。其算法复杂度为:O(N log(N) log(log(N))),该算法使用了傅里叶变换。
27、单纯型算法(Simplex Algorithm)——在数学的优化理论中,单纯型算法是常用的技术,用来找到线性规划问题的数值解。线性规划问题包括在一组实变量上的一系列线性不等式组,以及一个等待最大化(或最小化)的固定线性函数。
28、奇异值分解(Singular value decomposition,简称SVD)——在线性代数中,SVD是重要的实数或复数矩阵的分解方法,在信号处理和统计中有多种应用,比如计算矩阵的伪逆矩阵(以求解最小二乘法问题)、解决超定线性系统(overdetermined linear systems)、矩阵逼近、数值天气预报等等。
29、求解线性方程组(Solving a system of linear equations)——线性方程组是数学中最古老的问题,它们有很多应用,比如在数字信号处理、线性规划中的估算和预测、数值分析中的非线性问题逼近等等。求解线性方程组,可以使用高斯—约当消去法(Gauss-Jordan elimination),或是柯列斯基分解( Cholesky decomposition)。
Strukturtensor算法——应用于模式识别领域,为所有像素找出一种计算方法,看看该像素是否处于同质区域( homogenous region),看看它是否属于边缘,还是是一个顶点。
30、合并查找算法(Union-find)——给定一组元素,该算法常常用来把这些元素分为多个分离的、彼此不重合的组。不相交集(disjoint-set)的数据结构可以跟踪这样的切分方法。合并查找算法可以在此种数据结构上完成两个有用的操作:
I、查找:判断某特定元素属于哪个组。
II、合并:联合或合并两个组为一个组。
31、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
32、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
转载自: ChainGod(孙飞)
2019-10-28 17:06:19