为什么要用GPU来训练神经网络而不是CPU?
为什么要用GPU来训练神经网络而不是CPU?
-
因为cpu是串行执行指令的,就算是并行程序,细粒度上也是一条一条的串行执行,而gpu是真正的高并行计算,你想象一下,画一幅图,一笔一笔的画,和照相机卡擦定格下来的差距,那就是cpu和gpu做计算时的差距。而训练神经网络就是大量这样简单而重复的计算d
2018-01-21 22:36:55 -
因为神经网络有许许多多不需要复杂逻辑控制的计算(例如矩阵相乘),这适合gpu。并且gpu很适合单指令多数据运算(simd),典型的例子是非线性激活函数。
2018-01-20 22:01:14 -
GPU和CPU的工作原理不一样。个人电脑以及普通的服务器使用的通用型的处理器架构,按照复杂指令集进行运行,这样比较适合顺序执行。GPU就是一个强大的矢量运算器,比较适合图形渲染的相关操作。在深度学习中大部分都是硬浮点运算,很多矩阵运算,可以很好的使用GPU加速。
其实Intel开发了很多基于CPU的运算加速的库,能非常好的提供矩阵运算。我就看过一个因特尔的工程师,通过各种基于Intel的CPU的矩阵运算库将很好的实现了实时图像的处理,速度也很快。
2018-02-14 19:32:20 -
GPU为图形图像专门设计,在矩阵运算,数值计算方面具有独特优势,特别是浮点和并行计算上能优于CPU。还有GPU相对CPU干事少,高尖坚,没什么打扰,自然效率高。
2023-02-02 11:45:47 -
GPU为图形图像专门设计,在矩阵运算,数值计算方面具有独特优势,特别是浮点和并行计算上能优于CPU。还有GPU相对CPU干事少,高尖坚,没什么打扰,自然效率高。
2023-02-02 11:45:47 -
CPU和GPU都是可以训练神经网络的,相同的数据最终训练出的结果都是一样,区别是训练神经网络模型耗时不同。
CPU计算速度快,但一次只能处理少量数据,GPU计算速度慢于CPU,但GPU在处理大数据的计算时,并行计算能力要优于CPU。CPU就相当于高级跑车,速度快,性能优越,但载货能力不行。GPU就相当于大卡车,虽然速度慢,但挡不住载货能力强。训练神经网络时,对精度要求不是很高,依靠其超强的并行计算能力,训练一个神经网络的速度要比CPU快很多很多倍。GPU的并行计算就体现在下面图中一个个小格子上,每个格子就是一个计算单元,对于大数据的计算有其先天的优势。训练神经网需要调参,神经网络模型训练时间越短,调参时间就越短。用CPU训练模型耗时超长,十天半个月的调一次参,是很难让人忍受的。
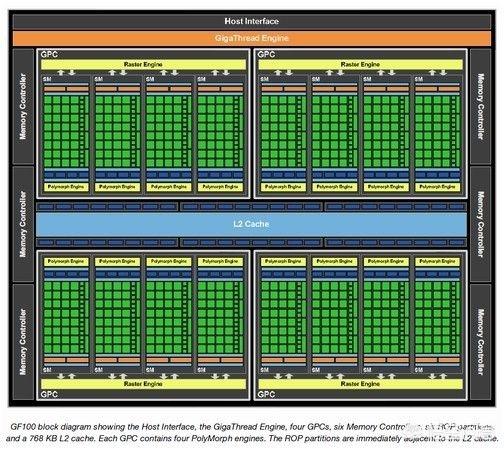
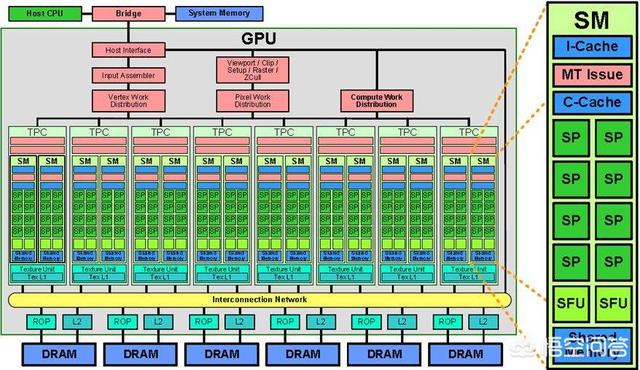 2019-08-27 19:14:51
2019-08-27 19:14:51 -
CPU和GPU都是可以训练神经网络的,相同的数据最终训练出的结果都是一样,区别是训练神经网络模型耗时不同。
CPU计算速度快,但一次只能处理少量数据,GPU计算速度慢于CPU,但GPU在处理大数据的计算时,并行计算能力要优于CPU。CPU就相当于高级跑车,速度快,性能优越,但载货能力不行。GPU就相当于大卡车,虽然速度慢,但挡不住载货能力强。训练神经网络时,对精度要求不是很高,依靠其超强的并行计算能力,训练一个神经网络的速度要比CPU快很多很多倍。GPU的并行计算就体现在下面图中一个个小格子上,每个格子就是一个计算单元,对于大数据的计算有其先天的优势。训练神经网需要调参,神经网络模型训练时间越短,调参时间就越短。用CPU训练模型耗时超长,十天半个月的调一次参,是很难让人忍受的。
2019-08-27 19:14:51 -
CPU 3g频率,假设32核心,共计每秒96g次处理能力,算上专用指令集的buff也难达到1000g的处理能力,gpu的话,1080ti为例,1.7g频率,3584个核心,既1.7x3584=6092g每秒的处理能力,比如浮点运算的时候还有x2的buff既12t的处理能力,知道为啥要用gpu了吧?(当然还有内存显存带宽优势)
2018-01-22 21:35:25 -
主要是GPU适合于矢量计算,它就是为多维数据计算而生的,专门用于处理图像、动画。一个简单的1024x768的RGB图,是一个1024x768x3的矩阵数据,然后各种图像切割、渲染等处理都要通过矩阵计算,这就是为何Photoshop占有内存和CPU高的原因。要是三维的图画就更复杂,要为各种图像建立三维物理坐标,建立数学矢量图形模型,这些点和面有颜色、材质、渲染、光影等属性。计算每一帧都要去做三维光学投影,计算出每个点在平面投影的位置、关系,还要通过物理学模型计算各个点的光影属性(光的强弱、是否遮挡、是否有阴影等)。如果是动画,还要按照几何、力学、光学等公式去模拟计算各个点的运动方向、速度等。GPU将这些常用图形图像算法直接实现到了硬件中,从而很短的指令周期就能完成如此大量数据的计算。
而通用CPU的硬件则是为运行指令、调度指令、提高运行效率、中断响应、多级缓存和读写、一般浮点运算、多流水线等常规应用而设计的。如果不是图像处理,CPU主要还是指令的执行,而非数据的运算。计算两个1024x768矩阵乘法,通用CPU需要上几百亿次通用加法乘法运算指令才能完成,而GPU只要几个指令就完成了。时间上,实际不会是几百亿倍效率,但是要高很多个数量级。所以,玩大型三维游戏时,普通CPU计算图像太慢,即使100%地全力运行,会发热,而且也还很卡;而GPU则轻松完成。
神级网络的计算涉及到大量的多维数据的处理,本质上与图像处理类似,虽然神经网络的算法不同于图像处理,但是其底层的数据计算还是多维矩阵运算,这就使得神经网络计算可以直接调用原本为图像处理而提供的指令和算法。
不过人工智能毕竟有一些自己独特的数学计算,而图像处理中没有用到,于是一些厂家就将这部分专门用于人工智能的算法又集成到硬件里,从而一个指令就能完成多步的人工智能算法计算,进一步提高人工智能算法的效率。这就是被他们用来宣传的AI芯片。
2018-08-28 08:47:01 -
因为神经网络计算属于数据密集型而非计算密集型的运算。虽然,每次迭代的运算都很简单,但每次参与运算的数据集却很大。
GPU恰恰是一种由很多简单计算单元构成的处理器,其结构是一种典型的高并发流水线结构,所以比较适合于这种数据密集型运算。
CPU则是一种由少量复杂计算单元构成的处理器,其更适合计算密集型运算。
若使用CPU进行神经网络计算,则会因存储器读写瓶颈导致计算单元利用率不高。具体表现是:计算单元从外存储器读写数据时,需反复占用数据总线,打断计算单元的工作。所以计算单元大多时间会处在空闲状态,导致CPU利用率很低,使算法整体完成时间拖得很长。
2018-08-25 13:55:27 -
gpu适合 大规模并行运算
2018-11-17 08:54:37 -

因为价格便宜....
其实任何应用...包括3D渲染...都是用CPU最好...问题在于128核的计算机的价格你可能承受不了....而你可能只需要掏10%的价格就能获得近似的性能...缺点就是你得单独另学一门语言...
所以个人以及小企业都喜欢用GPU…有品位的大企业都用CPU...
2018-01-22 13:42:12 -
使用GPU(图形处理器)来训练神经网络相比使用CPU(中央处理器)具有以下几个主要原因:
- 并行计算能力:GPU具有大量的计算核心和并行计算单元,相比于CPU而言,能够同时处理更多的数据和执行更多的计算操作。神经网络训练过程中的矩阵运算和张量操作可以被有效地并行化,因此GPU能够更快地执行这些计算任务,加速训练过程。
- 计算密集型任务:神经网络的训练过程通常需要大量的矩阵运算、向量操作和梯度计算等计算密集型任务。相较于CPU,GPU在执行这些任务时拥有更高的计算性能和吞吐量,能够更高效地处理大规模的神经网络模型和数据集。
- 深度学习框架支持:许多流行的深度学习框架(如TensorFlow和PyTorch)都提供了针对GPU加速的优化实现和接口,使得使用GPU进行神经网络训练变得更加方便和高效。这些框架通过将计算任务转化为GPU可执行的指令,利用GPU的并行计算能力来加速训练过程。
- 大规模模型和数据集:随着深度神经网络的不断发展,模型的规模和数据集的大小都在不断增加。使用GPU可以更好地应对大规模模型和数据集的训练需求,提高训练效率和加快迭代速度。
2023-05-28 09:06:53 -
使用GPU(图形处理器)来训练神经网络相比使用CPU(中央处理器)具有以下几个主要原因:
并行计算能力:GPU具有大量的计算核心和并行计算单元,相比于CPU而言,能够同时处理更多的数据和执行更多的计算操作。神经网络训练过程中的矩阵运算和张量操作可以被有效地并行化,因此GPU能够更快地执行这些计算任务,加速训练过程。
计算密集型任务:神经网络的训练过程通常需要大量的矩阵运算、向量操作和梯度计算等计算密集型任务。相较于CPU,GPU在执行这些任务时拥有更高的计算性能和吞吐量,能够更高效地处理大规模的神经网络模型和数据集。
深度学习框架支持:许多流行的深度学习框架(如TensorFlow和PyTorch)都提供了针对GPU加速的优化实现和接口,使得使用GPU进行神经网络训练变得更加方便和高效。这些框架通过将计算任务转化为GPU可执行的指令,利用GPU的并行计算能力来加速训练过程。
大规模模型和数据集:随着深度神经网络的不断发展,模型的规模和数据集的大小都在不断增加。使用GPU可以更好地应对大规模模型和数据集的训练需求,提高训练效率和加快迭代速度。
2023-05-28 09:06:53