程序员必须要掌握哪些算法?
程序员必须要掌握哪些算法?
-
优秀程序员该学的32个算法!!
1、A搜索算法——图形搜索算法,作为启发式搜索算法中的一种,这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法,常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。
从给定起点到给定终点计算出路径。其中使用了一种启发式的估算,为每个节点估算通过该节点的最佳路径,并以之为各个地点排定次序。算法以得到的次序访问这些节点。因此,A*搜索算法是最佳优先搜索的范例。
2、集束搜索(又名定向搜索,Beam Search)——最佳优先搜索算法的优化。使用启发式函数评估它检查的每个节点的能力。不过,集束搜索只能在每个深度中发现最前面的m个最符合条件的节点,m是固定数字——集束的宽度。
通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率
算法的工作流程如下:
使用广度优先策略建立搜索树,在树的每一层,按照启发代价对节点进行排序,然后仅留下预先确定的个数(Beam Width-集束宽度)的节点,仅这些节点在下一层次继续扩展,其他节点就被剪掉了。
将初始节点插入到list中,
将给节点出堆,如果该节点是目标节点,则算法结束;
否则扩展该节点,取集束宽度的节点入堆。然后到第二步继续循环。
算法结束的条件是找到最优解或者堆为空。
3、二分查找(Binary Search)——在线性数组中找特定值的算法,每个步骤去掉一半不符合要求的数据。
二分查找的基本思想是:
设R[low..high]是当前的查找区间
(1)首先确定该区间的中点位置:
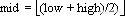
(2)然后将待查的K值与R[mid].key比较:若相等,则查找成功并返回此位置,否则须确定新的查找区间,继续二分查找,具体方法如下:
① 若R[mid].key>K,则由表的有序性可知R[mid..n].keys均大于K,因此若表中存在关键字等于K的结点,则该结点必定是在位置mid左边的子表R[1..mid-1]中,故新的查找区间是左子表R[1..mid-1]。
② 若R[mid].key<K,则要查找的K必在mid的右子表R[mid+1..n]中,即新的查找区间是右子表R[mid+1..n]。下一次查找是针对新的查找区间进行的。
4、分支界定算法(Branch and Bound)——在多种最优化问题中寻找特定最优化解决方案的算法,特别是针对离散、组合的最优化。
搜索策略是:
A产生当前扩展节点的所有孩子节点, 并且在活结点链表中删除当前拓展节点;对于一般的求最优值和资源问题是二叉树, 对于求最短路径这样的图论问题, 是一般的树
B在产生的孩子节点中,剪掉那些不可能产生可行解(或最优解)的节点;(使用限定条件)
C将其余所有的孩子节点加入活节点链表;
D从活结点表中选择下一个活结点作为新的扩展节点;
E遇到层结束标记(采取不同的数据结构实现可能不同, 加入新的结束标记)
如此循环,直到找到问题的可行解(或最优解)或者活结点表为空。
分支界定法的思想是:首先确定目标值的上下界, 边搜索边减掉搜索树的某些枝, 提高搜索效率。
5、Buchberger算法——一种数学算法,可将其视为针对单变量最大公约数求解的欧几里得算法和线性系统中高斯消元法的泛化。
6、数据压缩——采取特定编码方案,使用更少的字节数(或是其他信息承载单元)对信息编码的过程,又叫来源编码。
7、Diffie-Hellman密钥交换算法——一种加密协议,允许双方在事先不了解对方的情况下,在不安全的通信信道中,共同建立共享密钥。该密钥以后可与一个对称密码一起,加密后续通讯。
8、Dijkstra算法——针对没有负值权重边的有向图,计算其中的单一起点最短算法。
9、离散微分算法(Discrete differentiation)
10、动态规划算法(Dynamic Programming)——展示互相覆盖的子问题和最优子架构算法
11、欧几里得算法(Euclidean algorithm)——计算两个整数的最大公约数。最古老的算法之一,出现在公元前300前欧几里得的《几何原本》。
12、期望-最大算法(Expectation-maximization algorithm,又名EM-Training)——在统计计算中,期望-最大算法在概率模型中寻找可能性最大的参数估算值,其中模型依赖于未发现的潜在变量。EM在两个步骤中交替计算,第一步是计算期望,利用对隐藏变量的现有估计值,计算其最大可能估计值;第二步是最大化,最大化在第一步上求得的最大可能值来计算参数的值。
13、快速傅里叶变换(Fast Fourier transform,FFT)——计算离散的傅里叶变换(DFT)及其反转。该算法应用范围很广,从数字信号处理到解决偏微分方程,到快速计算大整数乘积。
14、梯度下降(Gradient descent)——一种数学上的最优化算法。
15、哈希算法(Hashing)
- Hash算法是一种只能加密不能解密的算法,可以将任意长度的信息转成杂乱的固定长度的字符串,叫做Hash值,又称“消息摘要”(Message Digest)
- 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
- 由于非对称算法的运算速度较慢,所以在数字签名协议中,哈希函数扮演了一个重要的角色而被用于数字签名。
哈希算法具有以下2个特点:
1.输入值只要改变一点,输出的hash值会天差地别。因此只有完全一样的输入值才能达到完全一样的输出值2.输入值和输出值之间没有规律,所以不能通过输出值反推出输入值。
16、堆排序(Heaps)
指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。
17、Karatsuba乘法——需要完成上千位整数的乘法的系统中使用,比如计算机代数系统和大数程序库,如果使用长乘法,速度太慢。该算法发现于1962年。
18、LLL算法(Lenstra-Lenstra-Lovasz lattice reduction)——以格规约(lattice)基数为输入,输出短正交向量基数。LLL算法在以下公共密钥加密方法中有大量使用:背包加密系统(knapsack)、有特定设置的RSA加密等等。
19、最大流量算法(Maximum flow)——该算法试图从一个流量网络中找到最大的流。它优势被定义为找到这样一个流的值。最大流问题可以看作更复杂的网络流问题的特定情况。最大流与网络中的界面有关,这就是最大流-最小截定理(Max-flow min-cut theorem)。Ford-Fulkerson 能找到一个流网络中的最大流。
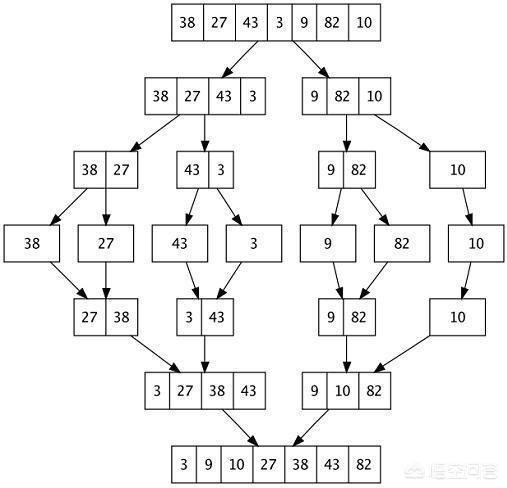
20、合并排序(Merge Sort)
具体步骤如下:
- 将待排序的数组分成左右两部分。
- 再将这两部分分别分成左右两部分。
- 一直分下去,直到不可分(每部分只有一个元素)。
- 由于数组被分成许多的单个数据,比较起来就简单了,然后开始合并,合并的同时排序。
- 持续合并直到得到排好序的数组。
下面这幅图可以帮助你理解算法过程:
21、牛顿法(Newton's method)——求非线性方程(组)零点的一种重要的迭代法。
同梯度下降法一样,是一种优化算法,其应用如可解决logistic回归于分类问题中的似然函数最大化。
其是一种用于求函数零点的数值方法。
22、Q-learning学习算法——这是一种通过学习动作值函数(action-value function)完成的强化学习算法,函数采取在给定状态的给定动作,并计算出期望的效用价值,在此后遵循固定的策略。Q-leanring的优势是,在不需要环境模型的情况下,可以对比可采纳行动的期望效用。
23、两次筛法(Quadratic Sieve)——现代整数因子分解算法,在实践中,是目前已知第二快的此类算法(仅次于数域筛法Number Field Sieve)。对于110位以下的十位整数,它仍是最快的,而且都认为它比数域筛法更简单。
24、RANSAC——是“RANdom SAmple Consensus”的缩写。该算法根据一系列观察得到的数据,数据中包含异常值,估算一个数学模型的参数值。其基本假设是:数据包含非异化值,也就是能够通过某些模型参数解释的值,异化值就是那些不符合模型的数据点。
25、RSA——公钥加密算法。首个适用于以签名作为加密的算法。RSA在电商行业中仍大规模使用,大家也相信它有足够安全长度的公钥。
26、Schönhage-Strassen算法——在数学中,Schönhage-Strassen算法是用来完成大整数的乘法的快速渐近算法。其算法复杂度为:O(N log(N) log(log(N))),该算法使用了傅里叶变换。
27、单纯型算法(Simplex Algorithm)——在数学的优化理论中,单纯型算法是常用的技术,用来找到线性规划问题的数值解。线性规划问题包括在一组实变量上的一系列线性不等式组,以及一个等待最大化(或最小化)的固定线性函数。
28、奇异值分解(Singular value decomposition,简称SVD)——在线性代数中,SVD是重要的实数或复数矩阵的分解方法,在信号处理和统计中有多种应用,比如计算矩阵的伪逆矩阵(以求解最小二乘法问题)、解决超定线性系统(overdetermined linear systems)、矩阵逼近、数值天气预报等等。
29、求解线性方程组(Solving a system of linear equations)——线性方程组是数学中最古老的问题,它们有很多应用,比如在数字信号处理、线性规划中的估算和预测、数值分析中的非线性问题逼近等等。求解线性方程组,可以使用高斯—约当消去法(Gauss-Jordan elimination),或是柯列斯基分解( Cholesky decomposition)。
Strukturtensor算法——应用于模式识别领域,为所有像素找出一种计算方法,看看该像素是否处于同质区域( homogenous region),看看它是否属于边缘,还是是一个顶点。
30、合并查找算法(Union-find)——给定一组元素,该算法常常用来把这些元素分为多个分离的、彼此不重合的组。不相交集(disjoint-set)的数据结构可以跟踪这样的切分方法。合并查找算法可以在此种数据结构上完成两个有用的操作:
I、查找:判断某特定元素属于哪个组。
II、合并:联合或合并两个组为一个组。
31、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
32、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
转载自: ChainGod(孙飞)
2019-10-28 17:06:19 - Hash算法是一种只能加密不能解密的算法,可以将任意长度的信息转成杂乱的固定长度的字符串,叫做Hash值,又称“消息摘要”(Message Digest)
-
使用红黑树来解决Hash碰撞冲突的问题;
计算sizeStamp的时候,调用了Interger中的方法,使用位运算来求出给定数leading zero的数量,当然使用sizeStamp这种方式也算是另辟蹊径吧;
presize中,使用位运算来求出不小于一个数的最小的2的幂;
transfer中,table[i]指向的链表或红黑树中的所有节点,根据hash\u0026n是否为0分别放在table[i]和table[i+n]中,之所以可以这样划分,是因为table数组的长度n是2的幂,这种数字关系挺微妙。
DelayQueue
take中,使用leader/follower模式,避免线程切换的开销,从而达到减少等待时间的目的。
PriorityBlockingQueue
使用数组维护了一个最小堆。
2019-12-06 11:39:29 -
你可以去力扣上看看,基本都得掌握
2019-12-06 09:23:46 -
去把数据结构的算法搞懂你就稳了
2019-12-06 11:44:58 -

一般的应用开发,什么算法也不需要。
高级开发,排序,数组,指针,循环
2019-12-06 12:14:27 -
这要看,你想做哪个方面的程序员。
程序员有后端、前端、移动端、大数据、AI等。如果只是纯前端和移动端而言,算法掌握基础的排序、红黑树、哈希等也就差不多了,更加高深的也用不到,更多的是系统API就提供了很多算法方法。总不见得,写的能比系统的好吧。如果只是想作为一个普通的程序员,不想着往高级和架构方向走,那么不接触算法,你会发现也行,活照做。但是呢,水往高处流,算法还是需要的。尤其像大数据和人工智能,算法是必须会的,而算法而言,就是数学。
人工智能来说,线性代数、概率论等是一个很重要的,不单是算法可以来解释。还有信息论,计算信息传递熵。个人推荐,可以看下国外的程序设计大赛,里面有很多考验算法的,平时开发中,多思考怎样减少信息传递,提高代码效率,这也是算法的一种。
必须了解,掌握的:1.树,2.哈希,3.正则,4.图算法,5.串匹配,6.运输流
但是更多的是掌握那些经典的数学计算算法,这才是根本。算法脱离不了数学,算法玩的好的,一般数学都好。推荐平时,多去看看《线性代数》《高等数学》还有偏向计算机的算法书籍,会有所帮助。再去看看国外程序设计大赛的题目,别人写的程序,从中会对算法有更大的启发。但作为程序员,算法只是一部分,更重要的是怎样快速迭代,减少开发成本,怎样贴合业务等。
2019-12-21 22:30:26 -
排序算法是基础,一定要会,然后再学tree,就差不多。
2019-12-18 07:27:28 -
从自己本身来看,数据结构里的算法都需要知道,从面试角度来说,二叉树、链表、冒泡、快速就必须要能写出来
2019-12-09 08:33:04 -
优秀程序员该学的32个算法!!
1、A搜索算法——图形搜索算法,作为启发式搜索算法中的一种,这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法,常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。
从给定起点到给定终点计算出路径。其中使用了一种启发式的估算,为每个节点估算通过该节点的最佳路径,并以之为各个地点排定次序。算法以得到的次序访问这些节点。因此,A*搜索算法是最佳优先搜索的范例。
2、集束搜索(又名定向搜索,Beam Search)——最佳优先搜索算法的优化。使用启发式函数评估它检查的每个节点的能力。不过,集束搜索只能在每个深度中发现最前面的m个最符合条件的节点,m是固定数字——集束的宽度。
通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率
算法的工作流程如下:
使用广度优先策略建立搜索树,在树的每一层,按照启发代价对节点进行排序,然后仅留下预先确定的个数(Beam Width-集束宽度)的节点,仅这些节点在下一层次继续扩展,其他节点就被剪掉了。
将初始节点插入到list中,
将给节点出堆,如果该节点是目标节点,则算法结束;
否则扩展该节点,取集束宽度的节点入堆。然后到第二步继续循环。
算法结束的条件是找到最优解或者堆为空。
3、二分查找(Binary Search)——在线性数组中找特定值的算法,每个步骤去掉一半不符合要求的数据。
二分查找的基本思想是:
设R[low..high]是当前的查找区间
(1)首先确定该区间的中点位置:
(2)然后将待查的K值与R[mid].key比较:若相等,则查找成功并返回此位置,否则须确定新的查找区间,继续二分查找,具体方法如下:
① 若R[mid].key\u003eK,则由表的有序性可知R[mid..n].keys均大于K,因此若表中存在关键字等于K的结点,则该结点必定是在位置mid左边的子表R[1..mid-1]中,故新的查找区间是左子表R[1..mid-1]。
② 若R[mid].key\u003cK,则要查找的K必在mid的右子表R[mid+1..n]中,即新的查找区间是右子表R[mid+1..n]。下一次查找是针对新的查找区间进行的。
4、分支界定算法(Branch and Bound)——在多种最优化问题中寻找特定最优化解决方案的算法,特别是针对离散、组合的最优化。
搜索策略是:
A产生当前扩展节点的所有孩子节点, 并且在活结点链表中删除当前拓展节点;对于一般的求最优值和资源问题是二叉树, 对于求最短路径这样的图论问题, 是一般的树
B在产生的孩子节点中,剪掉那些不可能产生可行解(或最优解)的节点;(使用限定条件)
C将其余所有的孩子节点加入活节点链表;
D从活结点表中选择下一个活结点作为新的扩展节点;
E遇到层结束标记(采取不同的数据结构实现可能不同, 加入新的结束标记)
如此循环,直到找到问题的可行解(或最优解)或者活结点表为空。
分支界定法的思想是:首先确定目标值的上下界, 边搜索边减掉搜索树的某些枝, 提高搜索效率。
5、Buchberger算法——一种数学算法,可将其视为针对单变量最大公约数求解的欧几里得算法和线性系统中高斯消元法的泛化。
6、数据压缩——采取特定编码方案,使用更少的字节数(或是其他信息承载单元)对信息编码的过程,又叫来源编码。
7、Diffie-Hellman密钥交换算法——一种加密协议,允许双方在事先不了解对方的情况下,在不安全的通信信道中,共同建立共享密钥。该密钥以后可与一个对称密码一起,加密后续通讯。
8、Dijkstra算法——针对没有负值权重边的有向图,计算其中的单一起点最短算法。
9、离散微分算法(Discrete differentiation)
10、动态规划算法(Dynamic Programming)——展示互相覆盖的子问题和最优子架构算法
11、欧几里得算法(Euclidean algorithm)——计算两个整数的最大公约数。最古老的算法之一,出现在公元前300前欧几里得的《几何原本》。
12、期望-最大算法(Expectation-maximization algorithm,又名EM-Training)——在统计计算中,期望-最大算法在概率模型中寻找可能性最大的参数估算值,其中模型依赖于未发现的潜在变量。EM在两个步骤中交替计算,第一步是计算期望,利用对隐藏变量的现有估计值,计算其最大可能估计值;第二步是最大化,最大化在第一步上求得的最大可能值来计算参数的值。
13、快速傅里叶变换(Fast Fourier transform,FFT)——计算离散的傅里叶变换(DFT)及其反转。该算法应用范围很广,从数字信号处理到解决偏微分方程,到快速计算大整数乘积。
14、梯度下降(Gradient descent)——一种数学上的最优化算法。
15、哈希算法(Hashing)
Hash算法是一种只能加密不能解密的算法,可以将任意长度的信息转成杂乱的固定长度的字符串,叫做Hash值,又称“消息摘要”(Message Digest)
也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
由于非对称算法的运算速度较慢,所以在数字签名协议中,哈希函数扮演了一个重要的角色而被用于数字签名。
哈希算法具有以下2个特点:
1.输入值只要改变一点,输出的hash值会天差地别。因此只有完全一样的输入值才能达到完全一样的输出值2.输入值和输出值之间没有规律,所以不能通过输出值反推出输入值。
16、堆排序(Heaps)
指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。
17、Karatsuba乘法——需要完成上千位整数的乘法的系统中使用,比如计算机代数系统和大数程序库,如果使用长乘法,速度太慢。该算法发现于1962年。
18、LLL算法(Lenstra-Lenstra-Lovasz lattice reduction)——以格规约(lattice)基数为输入,输出短正交向量基数。LLL算法在以下公共密钥加密方法中有大量使用:背包加密系统(knapsack)、有特定设置的RSA加密等等。
19、最大流量算法(Maximum flow)——该算法试图从一个流量网络中找到最大的流。它优势被定义为找到这样一个流的值。最大流问题可以看作更复杂的网络流问题的特定情况。最大流与网络中的界面有关,这就是最大流-最小截定理(Max-flow min-cut theorem)。Ford-Fulkerson 能找到一个流网络中的最大流。
20、合并排序(Merge Sort)
具体步骤如下:
将待排序的数组分成左右两部分。
再将这两部分分别分成左右两部分。
一直分下去,直到不可分(每部分只有一个元素)。
由于数组被分成许多的单个数据,比较起来就简单了,然后开始合并,合并的同时排序。
持续合并直到得到排好序的数组。
下面这幅图可以帮助你理解算法过程:
21、牛顿法(Newton's method)——求非线性方程(组)零点的一种重要的迭代法。
同梯度下降法一样,是一种优化算法,其应用如可解决logistic回归于分类问题中的似然函数最大化。
其是一种用于求函数零点的数值方法。
22、Q-learning学习算法——这是一种通过学习动作值函数(action-value function)完成的强化学习算法,函数采取在给定状态的给定动作,并计算出期望的效用价值,在此后遵循固定的策略。Q-leanring的优势是,在不需要环境模型的情况下,可以对比可采纳行动的期望效用。
23、两次筛法(Quadratic Sieve)——现代整数因子分解算法,在实践中,是目前已知第二快的此类算法(仅次于数域筛法Number Field Sieve)。对于110位以下的十位整数,它仍是最快的,而且都认为它比数域筛法更简单。
24、RANSAC——是“RANdom SAmple Consensus”的缩写。该算法根据一系列观察得到的数据,数据中包含异常值,估算一个数学模型的参数值。其基本假设是:数据包含非异化值,也就是能够通过某些模型参数解释的值,异化值就是那些不符合模型的数据点。
25、RSA——公钥加密算法。首个适用于以签名作为加密的算法。RSA在电商行业中仍大规模使用,大家也相信它有足够安全长度的公钥。
26、Schönhage-Strassen算法——在数学中,Schönhage-Strassen算法是用来完成大整数的乘法的快速渐近算法。其算法复杂度为:O(N log(N) log(log(N))),该算法使用了傅里叶变换。
27、单纯型算法(Simplex Algorithm)——在数学的优化理论中,单纯型算法是常用的技术,用来找到线性规划问题的数值解。线性规划问题包括在一组实变量上的一系列线性不等式组,以及一个等待最大化(或最小化)的固定线性函数。
28、奇异值分解(Singular value decomposition,简称SVD)——在线性代数中,SVD是重要的实数或复数矩阵的分解方法,在信号处理和统计中有多种应用,比如计算矩阵的伪逆矩阵(以求解最小二乘法问题)、解决超定线性系统(overdetermined linear systems)、矩阵逼近、数值天气预报等等。
29、求解线性方程组(Solving a system of linear equations)——线性方程组是数学中最古老的问题,它们有很多应用,比如在数字信号处理、线性规划中的估算和预测、数值分析中的非线性问题逼近等等。求解线性方程组,可以使用高斯—约当消去法(Gauss-Jordan elimination),或是柯列斯基分解( Cholesky decomposition)。
Strukturtensor算法——应用于模式识别领域,为所有像素找出一种计算方法,看看该像素是否处于同质区域( homogenous region),看看它是否属于边缘,还是是一个顶点。
30、合并查找算法(Union-find)——给定一组元素,该算法常常用来把这些元素分为多个分离的、彼此不重合的组。不相交集(disjoint-set)的数据结构可以跟踪这样的切分方法。合并查找算法可以在此种数据结构上完成两个有用的操作:
I、查找:判断某特定元素属于哪个组。
II、合并:联合或合并两个组为一个组。
31、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
32、维特比算法(Viterbi algorithm)——寻找隐藏状态最有可能序列的动态规划算法,这种序列被称为维特比路径,其结果是一系列可以观察到的事件,特别是在隐藏的Markov模型中。
转载自: ChainGod(孙飞)
2019-10-28 17:06:19